Chapter 10 Introduction to Data Science#
Data Science has become a fundamental component of any business or organization. It is the process of extracting insights and knowledge from data. The main goal of Data Science is to use statistical and computational methods to extract valuable insights from data. The insights obtained from the data can be used to make informed decisions in different fields.
In today’s world, data science has become an integral part of almost every organization. From healthcare to finance, marketing to sports, data science is playing a significant role in every field. The insights and knowledge derived from data can help businesses improve their products, increase revenue, and optimize their operations.
In this blog post, we will discuss some real-world examples of how data science is being used and why it is important.
Importance of Data Science
Data science helps in solving complex problems by analyzing large amounts of data. It helps in identifying patterns and trends that may not be visible to the human eye. With data science, we can extract insights and knowledge from data, which can help organizations make informed decisions. The insights obtained from data can help in:
Improving products and services - Data Science can help businesses analyze customer feedback, purchase history, and other data to improve their products and services.
Increasing revenue - Data Science can help businesses analyze customer behavior, optimize pricing strategies, and target customers more effectively to increase revenue.
Optimizing operations - Data Science can help businesses analyze data related to their operations to identify areas of improvement and optimize their processes.
Predicting future trends - Data Science can help businesses predict future trends based on historical data, which can help in planning and decision-making.
Real-world Examples of Data Science
Healthcare - Data Science is being used in healthcare to analyze patient data, develop new drugs, and improve patient outcomes. For example, data science can help in identifying patients who are at risk of developing a certain disease, which can help in early detection and treatment.
Finance - Data Science is being used in finance to analyze customer data, detect fraud, and optimize trading strategies. For example, data science can help in detecting fraudulent transactions by analyzing customer behavior patterns.
Marketing - Data Science is being used in marketing to analyze customer behavior, optimize pricing strategies, and target customers more effectively. For example, data science can help in predicting which customers are more likely to purchase a product, which can help in targeting those customers more effectively.
Conclusion
Data Science is an important field that is being used in various industries. It helps in extracting insights and knowledge from data, which can help organizations make informed decisions. With the increasing amount of data being generated every day, data science is becoming even more important. The insights obtained from data can help organizations improve their products and services, increase revenue, and optimize their operations.
Data Science and Data Analytics are two terms that are often used interchangeably, but they have distinct differences.
Data Science is the process of using statistical and computational methods to extract insights and knowledge from data. It involves multiple steps, such as data preparation, data exploration, data analysis, and communication of results. Data Science uses a wide range of tools and techniques, including statistical modeling, machine learning, and data visualization. The insights obtained from data can be used to solve complex problems, make informed decisions, and create predictive models. Data Science typically involves working with large, complex datasets and requires a strong understanding of mathematics and programming.
Data Analytics, on the other hand, is a subset of Data Science. It is focused on analyzing data to extract insights and information that can be used to make informed decisions. Data Analytics involves collecting, cleaning, and transforming data, and then using various analytical techniques to extract insights. The goal of Data Analytics is to answer specific questions or provide insights into a particular problem. It typically involves working with smaller datasets and uses a variety of analytical techniques such as descriptive statistics, visualization, and data mining.
The main difference between Data Science and Data Analytics is the scope of their objectives. Data Science aims to solve complex problems using a broad range of techniques and methods, while Data Analytics focuses on providing insights and answers to specific questions. Data Science involves working with larger, more complex datasets and requires a broad range of skills and knowledge, including statistical modeling, machine learning, and programming. Data Analytics involves working with smaller, more focused datasets and requires a strong understanding of data visualization, data mining, and statistical analysis.
In conclusion, while Data Science and Data Analytics are related fields, they have distinct differences in their objectives, methods, and scope. Both fields are essential for businesses and organizations that want to make informed decisions based on data-driven insights. Data Science can help organizations identify patterns, trends, and insights that may not be visible to the human eye, while Data Analytics can help organizations answer specific questions and provide insights into particular problems.
Plots in matplotlib#
import matplotlib.pyplot as plt
# Data
labels = ['January', 'February', 'March', 'April', 'May', 'June']
values = [10, 15, 20, 25, 30, 35]
# Create a bar chart
plt.bar(labels, values)
# Add titles and labels
plt.title('Monthly Sales')
plt.xlabel('Month')
plt.ylabel('Sales ($)')
# Display the chart
plt.show()
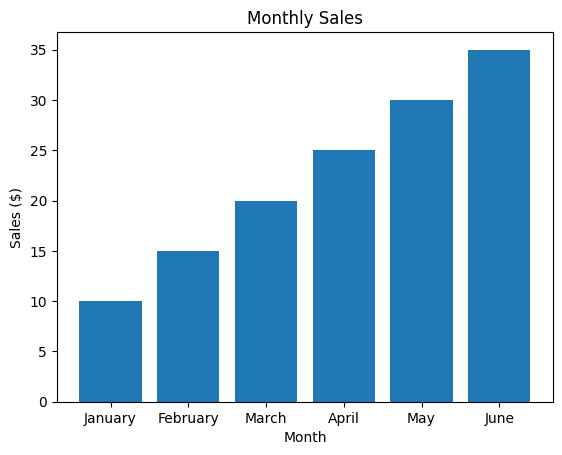
This code creates a simple bar chart with monthly sales data. The labels list contains the names of each month, while the values list contains the sales figures for each month.
The plt.bar() function is used to create the bar chart. It takes two arguments: the labels list and the values list.
The plt.title(), plt.xlabel(), and plt.ylabel() functions are used to add a title and labels to the chart.
Finally, the plt.show() function is called to display the chart.
Sure, here’s an example of how to plot a sample dataframe using pandas:
import pandas as pd
import matplotlib.pyplot as plt
# Sample data
data = {'year': [2016, 2017, 2018, 2019, 2020],
'sales': [1000, 1500, 2000, 2500, 3000],
'expenses': [800, 1000, 1200, 1500, 1800]}
# Create a pandas DataFrame
df = pd.DataFrame(data)
# Plot the data
df.plot(x='year', y=['sales', 'expenses'], kind='bar')
# Add titles and labels
plt.title('Sales and Expenses by Year')
plt.xlabel('Year')
plt.ylabel('Amount ($)')
# Display the chart
plt.show()
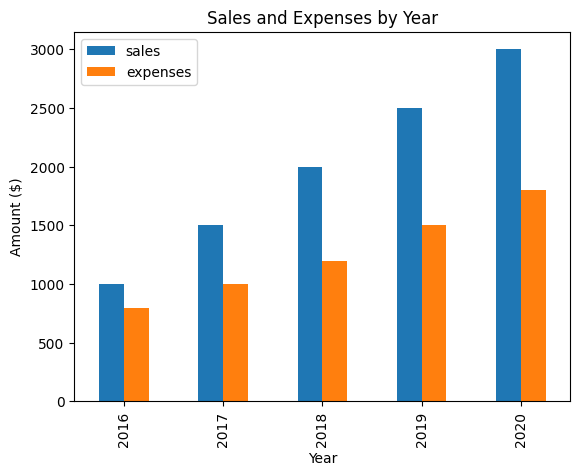
This code creates a pandas DataFrame with two columns (sales and expenses) and five rows, each representing a year from 2016 to 2020.
The df.plot() function is used to create a bar chart of the sales and expenses columns, with the year column used as the x-axis. The kind argument is set to 'bar' to create a bar chart.
The plt.title(), plt.xlabel(), and plt.ylabel() functions are used to add a title and labels to the chart.
Finally, the plt.show() function is called to display the chart.
Sure, here’s an example of how to use the requests library to get data from an API and load it into a pandas DataFrame:
import requests
import pandas as pd
# API endpoint
url = 'https://jsonplaceholder.typicode.com/posts'
# Make a GET request to the API endpoint
response = requests.get(url)
# Convert the response to a JSON object
data = response.json()
# Create a pandas DataFrame from the JSON object
df = pd.DataFrame(data)
# Display the first five rows of the DataFrame
print(df.head())
userId id title \
0 1 1 sunt aut facere repellat provident occaecati e...
1 1 2 qui est esse
2 1 3 ea molestias quasi exercitationem repellat qui...
3 1 4 eum et est occaecati
4 1 5 nesciunt quas odio
body
0 quia et suscipit\nsuscipit recusandae consequu...
1 est rerum tempore vitae\nsequi sint nihil repr...
2 et iusto sed quo iure\nvoluptatem occaecati om...
3 ullam et saepe reiciendis voluptatem adipisci\...
4 repudiandae veniam quaerat sunt sed\nalias aut...
This code makes a GET request to an API endpoint and stores the response in the response variable.
The response.json() method is used to convert the response to a JSON object.
The JSON object is then passed to the pd.DataFrame() function to create a pandas DataFrame.
Finally, the df.head() method is used to display the first five rows of the DataFrame.
Note that the specific API endpoint used in this example returns a list of posts, each with a userId, id, title, and body field. Depending on the API you’re using, you may need to adjust the code to match the format of the data returned by the API.
Web Scrapping with bs4 and pandas#
Pandas is an open-source Python library used for data manipulation and analysis. It is a powerful tool for handling structured data, such as spreadsheets and SQL tables. One of the most useful features of pandas is its ability to read and write data from various file formats, including CSV, Excel, and SQL databases.
Pandas can also be used for web scraping by reading data from HTML tables on web pages. The library provides a method called read_html() that can parse HTML tables and return a list of data frames. Data frames are two-dimensional tables with labeled rows and columns, similar to spreadsheets.
Here’s an example code snippet that uses pandas to scrape a table from a web page:
import pandas as pd
# URL of the web page containing the table
url = 'https://www.example.com/table.html'
# Read the HTML table into a list of data frames
dfs = pd.read_html(url)
# Extract the first data frame (assuming only one table on the page)
df = dfs[0]
# Print the first 5 rows of the data frame
print(df.head())
In this code snippet, we first import the pandas library using the import statement. We then specify the URL of the web page containing the table we want to scrape. We use the pd.read_html() method to read the HTML table into a list of data frames. Since read_html() can potentially return multiple data frames (if there are multiple tables on the page), we extract the first data frame using the index [0]. Finally, we print the first 5 rows of the data frame using the head() method.
Note that read_html() can handle some simple HTML tables, but may not work with more complex tables or tables that are embedded within other elements on the page. In such cases, we may need to use other web scraping techniques or libraries.
Overall, pandas is a powerful tool for web scraping and data analysis, and can save us a lot of time and effort when working with structured data on the web.
Beautiful Soup (bs4) is a Python library used for web scraping. It allows us to parse HTML and XML documents and extract information from them. One common use case for bs4 is to scrape data from tables on web pages.
To extract the data from a table using bs4, we first need to obtain the HTML source code of the web page containing the table. We can do this using the requests library, which allows us to make HTTP requests to web pages and retrieve their HTML content. Here’s an example code snippet that shows how to get the HTML source code of a web page:
import requests
# URL of the web page we want to scrape
url = 'https://www.example.com/table.html'
# Make a GET request to the URL and get the HTML content
response = requests.get(url)
html_content = response.content
# Print the HTML content
print(html_content)
In this code snippet, we first import the requests library using the import statement. We then specify the URL of the web page we want to scrape. We use the requests.get() method to make a GET request to the URL and retrieve the HTML content. We store the content in a variable called html_content and print it to the console.
Once we have the HTML source code of the web page, we can use bs4 to extract the table data. We start by creating a BeautifulSoup object and passing in the HTML content. We can then use the find() or find_all() methods to locate the table element(s) and extract their data. Here’s an example code snippet that shows how to extract the data from a table using bs4:
from bs4 import BeautifulSoup
# Create a BeautifulSoup object and pass in the HTML content
soup = BeautifulSoup(html_content, 'html.parser')
# Find the first table element on the page
table = soup.find('table')
# Loop through the rows of the table and extract the data
for row in table.find_all('tr'):
# Extract the data from each cell in the row
cells = row.find_all('td')
data = [cell.text.strip() for cell in cells]
# Print the data for this row
print(data)
In this code snippet, we first import the BeautifulSoup class from the bs4 library. We create a soup object by passing in the HTML content and specifying the parser to use (in this case, the built-in html.parser).
We then use the soup.find() method to find the first table element on the page. We can use the find_all() method to find all table elements on the page.
Next, we loop through the rows of the table using the find_all('tr') method. For each row, we extract the data from each cell using the find_all('td') method, which finds all td elements in the row. We then use a list comprehension to extract the text content of each cell and strip any whitespace using the text.strip() method.
Finally, we print the data for each row to the console. Note that this code snippet assumes that the table contains only text data. If the table contains other types of elements, such as links or images, we may need to modify the code to handle those cases.
Overall, bs4 is a powerful tool for web scraping, and can save us a lot of time and effort when working with HTML documents.
Pandas is a popular Python library for data analysis, manipulation, and cleaning. It is often used in data science projects, including web scraping, to process and analyze data in a tabular format.
To parse a table using pandas, we first need to obtain the HTML source code of the web page containing the table. We can do this using the requests library, as shown in the previous example. Once we have the HTML source code, we can use the read_html() method provided by pandas to parse the table data. Here’s an example code snippet that shows how to extract the data from a table using pandas:
import pandas as pd
# URL of the web page we want to scrape
url = 'https://www.example.com/table.html'
# Use pandas to read the table data from the URL
tables = pd.read_html(url)
# Print the first table
print(tables[0])
In this code snippet, we first import the pandas library using the import statement. We then specify the URL of the web page we want to scrape. We use the pd.read_html() method to read the table data from the URL and store the result in a variable called tables. This method returns a list of DataFrame objects, one for each table on the page.
In this example, we assume that the page contains only one table, so we print the first table using print(tables[0]). If the page contains multiple tables, we can print each table by looping through the list of DataFrame objects.
Pandas also provides several methods for manipulating and cleaning the data in the DataFrame objects. For example, we can use the drop() method to remove columns or rows with missing data, the fillna() method to fill in missing data with a default value, or the merge() method to combine multiple DataFrame objects into a single object.
Overall, pandas is a powerful tool for working with tabular data and can simplify the process of extracting and processing data from web pages.
Once we have parsed the table using pandas, we can easily output it to a CSV (comma-separated values) file using the to_csv() method provided by pandas. Here’s an example code snippet that shows how to output the table to a CSV file:
import pandas as pd
# URL of the web page we want to scrape
url = 'https://www.example.com/table.html'
# Use pandas to read the table data from the URL
tables = pd.read_html(url)
# Get the first table from the list
df = tables[0]
# Output the table to a CSV file
df.to_csv('table.csv', index=False)
In this code snippet, we first import the pandas library using the import statement. We then specify the URL of the web page we want to scrape and use pd.read_html() to read the table data from the URL and store it in the tables variable.
Next, we get the first table from the tables list and store it in a variable called df. We then use the to_csv() method to output the table to a CSV file called table.csv. The index=False parameter tells pandas not to include the row index numbers in the output file.
Once the code is executed, a CSV file called table.csv will be created in the current working directory with the data from the table. We can open this file in any spreadsheet application, such as Excel or Google Sheets, to view and manipulate the data further.
Overall, pandas makes it easy to output table data to a variety of file formats, including CSV, Excel, and SQL databases. This flexibility makes it a popular choice for data scientists and analysts who need to work with data from a variety of sources.
Pandas is a powerful library that provides many advanced features for cleaning and manipulating data. In this section, we’ll explore some of these features that can be used to clean the data extracted from a website.
Removing Duplicates: Sometimes a web page might have duplicate rows in its table, which can cause problems in our data analysis. Pandas provides a
drop_duplicates()method to remove duplicate rows from a DataFrame. Here’s an example code snippet:
import pandas as pd
# URL of the web page we want to scrape
url = 'https://www.example.com/table.html'
# Use pandas to read the table data from the URL
tables = pd.read_html(url)
# Get the first table from the list
df = tables[0]
# Drop duplicate rows
df.drop_duplicates(inplace=True)
In this example, we first parse the table using pandas and get the first table from the list of DataFrame objects. We then use the drop_duplicates() method to remove any duplicate rows in the table. The inplace=True parameter tells pandas to modify the DataFrame in place rather than returning a new DataFrame object.
Renaming Columns: The column names in a table might not always be in a format that’s suitable for our data analysis. Pandas provides a
rename()method to change the column names of a DataFrame. Here’s an example code snippet:
import pandas as pd
# URL of the web page we want to scrape
url = 'https://www.example.com/table.html'
# Use pandas to read the table data from the URL
tables = pd.read_html(url)
# Get the first table from the list
df = tables[0]
# Rename the columns
df = df.rename(columns={'old\_column\_name': 'new\_column\_name'})
In this example, we first parse the table using pandas and get the first table from the list of DataFrame objects. We then use the rename() method to change the name of a specific column in the DataFrame. The {'old_column_name': 'new_column_name'} parameter tells pandas to replace the old column name with the new column name.
Dealing with Missing Values: Web pages might have missing data in their tables, which can cause problems in our data analysis. Pandas provides several methods for dealing with missing values, including the
dropna()andfillna()methods.
The dropna() method removes any rows or columns with missing values from a DataFrame, while the fillna() method fills in the missing values with a default value or a value calculated from the other data in the DataFrame.
Here’s an example code snippet:
import pandas as pd
# URL of the web page we want to scrape
url = 'https://www.example.com/table.html'
# Use pandas to read the table data from the URL
tables = pd.read_html(url)
# Get the first table from the list
df = tables[0]
# Remove rows with missing data
df = df.dropna()
# Fill in missing data with a default value
df = df.fillna(0)
In this example, we first parse the table using pandas and get the first table from the list of DataFrame objects. We then use the dropna() method to remove any rows with missing data from the DataFrame. We then use the fillna() method to fill in any remaining missing data with the value 0.
Overall, pandas provides a wide range of features for cleaning and manipulating data, which makes it a popular choice for data scientists and analysts. By using these advanced features, we can transform raw data extracted from a website into a format that’s suitable for our data analysis.
Jupyter Notebooks#
Jupyter notebooks are interactive computing environments that allow you to create and share documents that contain live code, equations, visualizations, and narrative text. They are widely used in data science, scientific computing, and education, among other fields.
At its core, a Jupyter notebook consists of a JSON file that contains a set of cells. Each cell can contain code, markdown, or raw text. Code cells allow you to write and execute code interactively, while markdown cells allow you to write formatted text using the Markdown syntax. Raw text cells allow you to write plain text that will be included in the notebook as-is.
When you create a new Jupyter notebook, you are presented with an interface that allows you to create, edit, and run cells. The interface is typically divided into two main areas: the notebook toolbar and the notebook cells.
The notebook toolbar contains various options for working with the notebook, such as creating new cells, saving the notebook, and changing the notebook’s kernel. The kernel is the computational engine that executes the code in the notebook. By default, Jupyter notebooks use a Python kernel, but you can also use kernels for other languages such as R and Julia.
The notebook cells are where you write and run code. Each cell can be executed independently of the others, allowing you to test and iterate on your code. When you run a code cell, the kernel executes the code and returns the output below the cell. This output can include text, tables, charts, and other visualizations.
One of the main advantages of Jupyter notebooks is that they allow you to combine code, text, and visualizations in a single document. This makes it easy to create and share reproducible analyses and reports, as well as interactive tutorials and educational materials.
In addition, Jupyter notebooks are highly extensible, with a large ecosystem of plugins and extensions that allow you to customize the user interface, add new functionality, and integrate with other tools and services.
Overall, Jupyter notebooks provide a powerful and flexible environment for interactive computing, data analysis, and scientific communication. Whether you’re a data scientist, a researcher, or an educator, Jupyter notebooks can help you work more efficiently and collaborate more effectively.