Chapter 11 Python Projects#
Using argparse#
argparse is a Python module that makes it easy to write command-line interfaces. It allows you to specify the arguments that your program should accept in a clean and organized way, and it takes care of handling the input and output for you.
Here’s an example of how to use argparse to parse command-line arguments in a Python script:
argparse is a Python module that makes it easy to write command-line interfaces. It allows you to specify the arguments that your program should accept in a clean and organized way, and it takes care of handling the input and output for you.
Here's an example of how to use argparse to parse command-line arguments in a Python script:
This script defines a single command-line argument, –sum, which specifies whether the program should sum or find the maximum of the integers. If the –sum argument is not provided, the default action is to find the maximum.
To run this script, you would type something like python script.py 1 2 3 –sum at the command line. This would cause the script to print 6, which is the sum of the integers 1, 2, and 3.
Here’s an example of how you might use argparse to write a command-line interface for a program that keeps track of the books that a bear has read:
import argparse
parser = argparse.ArgumentParser(description='Bear book tracker')
# Add a command to add a book to the bear's reading list
parser.add_argument('--add', dest='book', type=str,
help='add a book to the reading list')
# Add a command to list the books that the bear has read
parser.add_argument('--list', action='store_true',
help='list the books that the bear has read')
# Parse the arguments
args = parser.parse_args()
# Initialize an empty list to store the bear's books
books = []
# If the --add argument was provided, add the book to the list
if args.book:
books.append(args.book)
# If the --list argument was provided, print the list of books
if args.list:
print("Bear's books:")
for book in books:
print(book)
To use this program, you would type something like python book_tracker.py –add “The Giving Tree” to add a book to the bear’s reading list, or python book_tracker.py –list to view the list of books.
I hope this helps give you a basic understanding of how argparse works!
Convert pdf to pngs#
ImageMagick is a software suite to create, edit, and compose bitmap images. It can read, convert and write images in a variety of formats (over 100) including DPX, EXR, GIF, JPEG, JPEG-2000, PDF, PhotoCD, PNG, Postscript, SVG, and TIFF. ImageMagick is used to translate, flip, mirror, rotate, scale, shear and transform images, adjust image colors, apply various special effects, or draw text, lines, polyglines, ellipses and Bézier curves.
It is used by graphic designers, photographers, scientists and also used for creating thumbnails for websites, creating GIF animations, converting PDF pages to images and so on. ImageMagick can be used from the command-line or can be used as a programming library for software development.
You can call ImageMagick from Python using the os module, which provides a way to interface with the underlying operating system.
Here’s an example of how to use ImageMagick to convert an image from one format to another:
import os
input_image = 'input.jpg'
output_image = 'output.png'
os.system(f'convert {input_image} {output_image}')
In this example, convert is the command-line utility provided by ImageMagick to convert images. The input_image variable specifies the path to the input image and output_image specifies the path to the output image. The os.system function is used to run the convert command, which converts the input image to the output image.
The convert utility is only available in imagemagick 6.
Note that this method is prone to security vulnerabilities, since it passes the parameters directly to the shell. To avoid these vulnerabilities, you can use the subprocess module, which provides a more secure way of calling shell commands. Here’s an example of how to use the subprocess module to call ImageMagick:
import subprocess
input_image = 'input.jpg'
output_image = 'output.png'
subprocess.run(['convert', input_image, output_image])
In this example, the subprocess.run function is used to run the convert command, and the parameters are passed as a list, rather than as a string. This is a more secure way of calling shell commands, as it avoids shell injection attacks.
You can call ImageMagick from Python using the os module, which provides a way to interface with the underlying operating system.
Here’s an example of how to use ImageMagick to convert an image from one format to another:
import os
input_image = 'input.jpg'
output_image = 'output.png'
os.system(f'convert {input_image} {output\_image}')`
In this example, convert is the command-line utility provided by ImageMagick to convert images. The input_image variable specifies the path to the input image and output_image specifies the path to the output image. The os.system function is used to run the convert command, which converts the input image to the output image.
Note that this method is prone to security vulnerabilities, since it passes the parameters directly to the shell. To avoid these vulnerabilities, you can use the subprocess module, which provides a more secure way of calling shell commands. Here’s an example of how to use the subprocess module to call ImageMagick:
import subprocess
input_image = 'input.jpg'
output_image = 'output.png'
subprocess.run(['convert', input_image, output_image])`
In this example, the subprocess.run function is used to run the convert command, and the parameters are passed as a list, rather than as a string. This is a more secure way of calling shell commands, as it avoids shell injection attacks.
import os
def main():
dir_list = os.listdir('.')
for full_file_name in dir_list:
base_name, extension = os.path.splitext(full_file_name)
if extension == '.pdf': # then .pdf file --> convert to image!
cmd_str = ' '.join(['convert',
'-density 400',
full_file_name,
'-flatten',
base_name + '.png'])
print(cmd_str) # echo command to terminal
os.system(cmd_str) # execute command
if __name__ == '__main__':
main()
This is a Python script that uses the os module to convert all PDF files in the current directory to PNG images using ImageMagick. The main function lists all the files in the current directory using os.listdir, and then loops through each file name in dir_list. If the file extension is ‘.pdf’, the script splits the file name into its base name and extension using os.path.splitext, and then creates a command string using cmd_str that calls ImageMagick’s convert utility with the specified options.
The options used in this script are:
density 400: sets the density of the output image, which affects its resolution.
flatten: combines all the layers of the PDF into a single image.
The os.system function is then used to execute the command string, which converts the PDF file to a PNG image. The script prints the command string to the terminal to show what it’s doing, and the result is a set of PNG images, one for each PDF file in the directory.
ImageMagick is a versatile and powerful software suite that has many uses, including:
Image Conversion: ImageMagick can be used to convert images from one format to another, making it easier to work with different image formats.
Image Editing: ImageMagick can be used to perform basic image editing operations, such as cropping, resizing, rotating, and flipping images.
Image Compression: ImageMagick can be used to compress images, reducing their file size while maintaining image quality.
Image Manipulation: ImageMagick can be used to manipulate images in various ways, such as applying special effects, adding text and shapes, and blending multiple images together.
Thumbnail Creation: ImageMagick can be used to create thumbnails for websites, making it easier to manage large numbers of images.
Image Animation: ImageMagick can be used to create GIF animations from a sequence of images.
PDF Conversion: ImageMagick can be used to convert PDF pages to images, making it easier to work with PDF documents.
Image Processing: ImageMagick can be used for image processing tasks, such as adjusting image colors and removing noise from images.
Scientific Visualization: ImageMagick can be used in scientific visualization, such as for rendering 3D models or visualizing data.
These are just a few examples of the many uses of ImageMagick. It is a highly versatile software suite that can be used in many different ways to work with images.
References#
Chat gpt blog generation#
ChatGPT is a large language model that has been trained using a technique called unsupervised learning, in which the model learns to generate text by being fed a large dataset of text. It is designed to generate human-like responses to prompts, and can be used for a variety of natural language processing tasks, such as language translation, text summarization, and question answering.
import os
import re
import argparse
from pyChatGPT import ChatGPT
# import yaml
from yaml import load, dump, Loader
import io
import warnings
from PIL import Image
from stability_sdk import client
import stability_sdk.interfaces.gooseai.generation.generation_pb2 as generation
# Our Host URL should not be prepended with "https" nor should it have a trailing slash.
os.environ['STABILITY_HOST'] = 'grpc.stability.ai:443'
os.environ["STABILITY_KEY"] = os.getenv("STABILITY_KEY")
def generate_image(cfg:dict)-> None:
prompt = cfg['imageArgs']['prompt']
stability_api = client.StabilityInference(
key=os.environ['STABILITY_KEY'], # API Key reference.
verbose=True, # Print debug messages.
engine="stable-diffusion-v1-5", # Set the engine to use for generation.
# Available engines: stable-diffusion-v1 stable-diffusion-v1-5 stable-diffusion-512-v2-0 stable-diffusion-768-v2-0
# stable-diffusion-512-v2-1 stable-diffusion-768-v2-1 stable-inpainting-v1-0 stable-inpainting-512-v2-0
)
answers = stability_api.generate(
prompt=prompt
)
for resp in answers:
for artifact in resp.artifacts:
if artifact.finish_reason == generation.FILTER:
warnings.warn(
"Your request activated the API's safety filters and could not be processed."
"Please modify the prompt and try again.")
if artifact.type == generation.ARTIFACT_IMAGE:
img = Image.open(io.BytesIO(artifact.binary))
# images
img.save("images" + "/" + str(artifact.seed)+ ".png") # Save our generated images with their seed number as the filename.
def generate_frontmatter(cfg: dict)-> None:
# open output file
output_file = cfg['outputFile']
with open(output_file, 'w') as f:
# write frontmatter
f.write('---\n')
# get frontmatter
frontmatter = cfg['frontMatter']
for key, value in frontmatter.items():
f.write(f'{key}: {value}\n')
f.write('---\n')
# write body
pass
def use_programming_language(cfg: dict, section_text: str)-> None:
# get programming language
programming_language = cfg['programmingLanguage']
# use regex to find plain ``` and replace with ```programming_language
type_start_line = None
type_end_line = None
# replace with code blocks with programming language
# split lines by \n
modified_lines = []
lines = section_text.split('\n')
for i, line in enumerate(lines):
if line == '```':
if type_start_line is None:
type_start_line = i
# append modified line
modified_lines.append(f'```{programming_language}')
else:
# odd number of ``` so we are ending a code block
type_start_line = None
# append modified line
modified_lines.append('```')
else:
# adjust line if type_start_line is not None
# remove ` at the beginning of the line and the end of the line
if type_start_line is not None:
# check for ` character at the beginning of the line
if line[0] == '`':
line = line[1:]
# check for ` character at the end of the line
if line[-1] == '`':
line = line[:-1]
modified_lines.append(line)
return "\n".join(modified_lines)
def generate_body(cfg: dict)-> None:
# read CHATGPT_TOKEN from os
CHATGPT_SESSION_TOKEN = os.getenv("CHATGPT_TOKEN")
# print(CHATGPT_SESSION_TOKEN)
session_token = CHATGPT_SESSION_TOKEN # `__Secure-next-auth.session-token` cookie from https://chat.openai.com/chat
api = ChatGPT(session_token) # auth with session token
output_file = cfg['outputFile']
sections = cfg['sections']
with open(output_file, 'a') as f:
for section in sections:
# check if str or dict
if isinstance(section, str):
resp = api.send_message(section)
clean_message = use_programming_language(cfg, resp['message'])
else:
# assume dict
# type and src from dict
input_type = section['type']
src = section['src']
if input_type == 'file':
# read src from file
with open(src, 'r') as src_file:
src_text = src_file.read()
resp = api.send_message(src_text)
clean_message = resp['message']
print(clean_message)
# write original text
programming_language = cfg['programmingLanguage']
f.write(f"```{programming_language} \n {src_text} \n ```\n")
f.write('\n')
f.write(clean_message)
f.write('\n')
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--file', type=str, default='posts/chatgpt_blog_generation.yml')
args = parser.parse_args()
# valid files exist
# argparse for file eventually
with open(args.file, 'r') as f:
cfg = load(f, Loader=Loader)
# if file exists skip
# if not run these functions
if os.path.exists(cfg['outputFile']):
print('file exists')
exit(0)
# if genImage is true, then makeImage
if cfg['imageArgs']:
generate_image(cfg)
pass
generate_frontmatter(cfg)
generate_body(cfg)
This is a Python script that uses the ChatGPT API, the pyChatGPT library, and the stability_sdk to generate text and images. The script takes in a configuration file in YAML format, which specifies the input text, the output file, and various settings such as the programming language to use for code blocks and the prompt for the image generation. It uses the ChatGPT API to generate text in response to prompts specified in the configuration file. The script also uses the stability_sdk to generate images based on the prompt specified in the configuration file. The script also uses the Python Imaging Library (PIL) to save the generated images to a directory. Additionally, it processes the generated text, using regular expressions to replace plain backticks with code blocks in the specified programming language.
There are several ways to monetize a blog, including the following:
Advertising: You can place ads on your blog and earn money through pay-per-click or pay-per-impression programs such as Google AdSense.
Affiliate marketing: You can earn money by promoting other people’s products or services and receiving a commission for every sale made through your unique affiliate link.
Sponsored posts: You can write posts sponsored by a brand or company and receive payment for the promotion.
Selling products or services: You can sell your own products or services, such as e-books, courses, or consulting services, directly to your readers.
Crowdfunding: You can use platforms like Patreon or Kickstarter to raise money from your readers to support your blog or other projects.
Subscription models: You can offer exclusive content, access to a community or other perks for a recurring fee.
It’s important to note that monetizing your blog requires consistent, high-quality content, and a sizable audience. It may take some time and effort to grow your blog and monetize it successfully.
Using AI to generate images can be beneficial in a variety of ways. Some reasons include:
Automation: AI-generated images can be produced quickly and at scale, reducing the time and resources required to create images manually.
Variation: AI-generated images can be easily customized to produce a wide range of variations, allowing for greater flexibility in image design.
Consistency: AI-generated images can be designed to maintain a consistent style or theme, making it easier to maintain a cohesive visual identity across a brand or product.
Cost-effectiveness: AI-generated images can be less expensive than hiring a professional photographer or graphic designer, making them more accessible to businesses with limited budgets.
Creative possibilities: AI-generated images can be used in creative ways, such as creating surreal or abstract imagery that would be difficult to achieve through traditional means.
Personalization: AI-generated images can be used to personalize content for targeted audience, resulting in higher engagement and conversion rates.
Efficiency: AI-generated images can be used to generate high-quality images for use in various applications, such as product advertising, web design, and mobile apps.
Using AI to generate images can be beneficial in a variety of ways. Some reasons include:
Automation: AI-generated images can be produced quickly and at scale, reducing the time and resources required to create images manually.
Variation: AI-generated images can be easily customized to produce a wide range of variations, allowing for greater flexibility in image design.
Consistency: AI-generated images can be designed to maintain a consistent style or theme, making it easier to maintain a cohesive visual identity across a brand or product.
Cost-effectiveness: AI-generated images can be less expensive than hiring a professional photographer or graphic designer, making them more accessible to businesses with limited budgets.
Creative possibilities: AI-generated images can be used in creative ways, such as creating surreal or abstract imagery that would be difficult to achieve through traditional means.
Personalization: AI-generated images can be used to personalize content for targeted audience, resulting in higher engagement and conversion rates.
Efficiency: AI-generated images can be used to generate high-quality images for use in various applications, such as product advertising, web design, and mobile apps.
AI has the potential to change blog writing in the future by making the process more efficient and personalized. For example, AI-powered writing assistants can help writers generate content faster by suggesting topics, outlining structure, and providing research and data to support their ideas. Additionally, AI-powered content generation can personalize blogs by analyzing audience data and tailoring the content to their interests and preferences. It can also generate images, infographics and videos to supplement the written content. However, it’s important to note that AI-generated content should be carefully evaluated for accuracy and bias, and should be used in conjunction with human editing and oversight to ensure high-quality and ethical results.
References#
Investor document downloader#
CSE exchange refers to the Canadian Securities Exchange, which is a stock exchange located in Canada. The CSE is a fully electronic exchange that provides a marketplace for the trading of securities listed on its platform. It offers a range of listing options, including equity, debt, and structured products, and operates with a focus on serving emerging and growth companies. The exchange aims to provide an efficient, transparent, and accessible marketplace for issuers and investors, and is regulated by the Ontario Securities Commission.
Downloading reports from the CSE exchange can provide valuable information for investors, traders, and other market participants. The reports contain data on market activity, financial performance, and other key metrics for the companies listed on the exchange. By accessing these reports, you can gain insight into the financial health and performance of the companies, which can help inform your investment decisions.
For example, the CSE provides annual and quarterly financial statements, press releases, and other disclosures for companies listed on the exchange. By downloading and reviewing these reports, you can get a better understanding of a company’s financial performance, including revenue, expenses, profits, and growth trends. This information can help you make more informed decisions about whether to buy, sell, or hold a company’s stock.
Additionally, downloading CSE reports can provide you with insights into the overall health of the Canadian securities market, as well as emerging trends and opportunities. This information can be especially useful for traders and investors looking to make strategic decisions about their portfolios.
In summary, downloading reports from the CSE exchange can provide valuable information for market participants and
import pandas as pd
import time
import os
import requests
import json
from cad_tickers.exchanges.cse import get_recent_docs_from_url
from extract_doc import mk_dir, handle_logic
from io import BytesIO, StringIO
"""
1. Get the list of documents from the CSE website
2. For each document, get the document url
3. If the document url is not in the csv file, add it to the csv file
4. For each document url, download the document and add it to the docs folder
5. For each document url, make a discord request with the document url
6. For each document url, make a discord request with the document summary
"""
def fig_to_buffer(fig):
""" returns a matplotlib figure as a buffer
"""
buf = BytesIO()
fig.savefig(buf, format='png')
buf.seek(0)
imgdata = buf.read()
return imgdata
def make_discord_request(content, embeds = [], filename = None, file = None):
url = os.getenv("DISCORD_WEBHOOK")
if url == None:
print('DISCORD_WEBHOOK Missing')
pass
data = {}
data["content"] = content
files = {'file': (filename, file, 'application/pdf')}
if filename != None and file != None:
resp = requests.post(
url, data=data, files=files
)
elif len(embeds) != 0:
data["embeds"] = embeds
resp = requests.post(
url, data=json.dumps(data), headers={"Content-Type": "application/json"}
)
print(resp)
This code is a Python script that downloads documents from the Canadian Securities Exchange (CSE) website and makes a Discord request with the document URL and summary. Here’s a brief overview of what it does:
It retrieves a list of documents from the CSE website using the
get_recent_docs_from_urlfunction.For each document, it retrieves the document URL.
If the document URL is not already in a CSV file, it adds it to the CSV file.
It downloads the document and saves it to a directory called
docs.For each document URL, it makes a Discord request with the document URL.
For each document URL, it makes another Discord request with the document summary.
The Discord request is sent using the requests library. The make_discord_request function takes in several arguments, including the content, embeds, filename, and file data. If the filename and file data are provided, the function makes a request with the file attached. If the embeds argument is provided, the function makes a request with the embeds data. The URL for the Discord webhook is read from an environment variable DISCORD_WEBHOOK.
stockList = ["PKK", "IDK", "ADDC", "VPH", "VST", "ACT"]
def get_cse_tickers_data():
url = "https://github.com/FriendlyUser/cad_tickers_list/blob/main/static/latest/cse.csv?raw=true"
r = requests.get(url, allow_redirects=True)
s = r.content
return pd.read_csv(StringIO(s.decode('utf-8')))
stock_df = get_cse_tickers_data()
stock_rows = stock_df.loc[stock_df['Symbol'].isin(stockList)]
stock_rows.loc[:, 'stock'] = stock_rows['Symbol']
stock_rows.loc[:, 'url'] = stock_rows['urls']
stockUrls = stock_rows.to_dict('records')
csv_file = "docs.csv"
if os.path.isfile(csv_file):
# read from csv
df = pd.read_csv(csv_file)
else:
# make new df
df = pd.DataFrame(columns=["stock", "url", "docUrl"])
This code is retrieving data for a list of stocks (stockList) from the Canadian Securities Exchange (CSE). It uses the get_cse_tickers_data function to retrieve the data from a CSV file hosted on GitHub, which contains information about CSE stocks, such as their symbol, name, and URLs. The function uses the requests library to make a GET request to the URL of the CSV file, and the returned content is then converted into a Pandas DataFrame using pd.read_csv.
Next, the code filters the data for only the stocks in the stockList by using the loc method on the DataFrame and checking if the value in the Symbol column is in the stockList using the isin method. The filtered data is then saved in the stock_rows DataFrame.
The code then creates two new columns in the stock_rows DataFrame, one named stock and the other named url, which contain the values from the Symbol and urls columns, respectively. The filtered data is then converted into a list of dictionaries (stockUrls) using the to_dict method.
Finally, the code checks if there is an existing CSV file named docs.csv in the current directory. If there is, it reads the data into a DataFrame using `pd.
for stock in stockUrls:
stockName = stock.get("stock")
stockUrl = stock.get("url")
urls = []
try:
urls = get_recent_docs_from_url(stockUrl)
except Exception as e:
pass
for docUrl in urls:
# skip malformed relative urls
if docUrl[0] == '/':
continue
# add each element to list
exists = docUrl in df["docUrl"].tolist()
if exists == False:
print(f"Adding {stockName}: {docUrl}")
df.loc[len(df)] = [stockName, stockUrl, docUrl]
# wrap in todo
stock_doc_dir = f"docs/{stockName}"
mk_dir(stock_doc_dir)
stock_doc_file_path = docUrl.split("/")[-1]
pdf_file_name = f"{stock_doc_dir}/{stock_doc_file_path}.pdf"
companyName = stock.get("Company").\
replace('Inc.', '').\
replace('Pharma', '').\
strip()
dataDict = {
"url": docUrl,
"path": pdf_file_name,
"company_name": companyName
}
result_obj = handle_logic(dataDict)
file_contents = result_obj.get("contents")
summary = "N/A"
try:
summary = result_obj.get("summary")[:1980]
except TypeError as e:
pass
embeds = [
{
"title": stockName,
"url": docUrl,
"description": summary
}
]
if file_contents != None:
make_discord_request(f"*{stockName}*: \n {docUrl}", embeds, pdf_file_name, file_contents)
time.sleep(2)
else:
make_discord_request(f"*{stockName}*: \n {docUrl}", embeds)
time.sleep(1)
pass
df = df.drop_duplicates()
df = df.sort_values(by=['stock'])
df.to_csv(csv_file, index=False)
This code is a script that downloads and summarizes recent documents from a list of stock symbols. The stock symbols are stored in the list stockList, and the data for these symbols is obtained by calling the get_cse_tickers_data function, which retrieves data from a CSV file stored on GitHub.
The code then loops through each of the stocks in stockList, and for each stock, it retrieves a list of recent documents by calling the get_recent_docs_from_url function and passing it the URL for the stock.
For each document, the code checks if the document URL already exists in the DataFrame df. If the URL does not exist, the code adds the document information (i.e., stock name, URL, and a summary) to df and makes a Discord request to post the information to a Discord channel. The information posted to the Discord channel includes the stock name, document URL, and a summary of the document’s contents. If the contents of the document are available, they are also included in the Discord request as an attachment.
After all the documents have been processed, the code removes any duplicates in df and sorts the entries by the stock name. Finally, the updated df is saved to a CSV file.
References#
Generate Subtitles for Youtube Videos#
Transcribing videos is important for several reasons. Firstly, it makes the content of the video more accessible to people who are deaf or hard of hearing. Secondly, it can improve search engine optimization (SEO) as the text in the transcription can be indexed by search engines. Thirdly, it can make it easier to create captions or subtitles for the video, which can again make it more accessible to a wider audience. Finally, transcribing videos can be useful for researchers or content creators who want to analyze the content of the video or repurpose it in other ways.
import whisper
import gradio as gr
import ffmpeg
from yt_dlp import YoutubeDL
import os
import sys
from subprocess import PIPE, run
youtube_livestream_codes = [
91,
92,
93,
94,
95,
96,
300,
301,
]
youtube_mp4_codes = [
298,
18,
22,
140,
133,
134
]
def second_to_timecode(x: float) -> str:
hour, x = divmod(x, 3600)
minute, x = divmod(x, 60)
second, x = divmod(x, 1)
millisecond = int(x * 1000.)
return '%.2d:%.2d:%.2d,%.3d' % (hour, minute, second, millisecond)
def get_video_metadata(video_url: str = "https://www.youtube.com/watch?v=21X5lGlDOfg&ab_channel=NASA")-> dict:
with YoutubeDL({'outtmpl': '%(id)s.%(ext)s'}) as ydl:
info_dict = ydl.extract_info(video_url, download=False)
video_title = info_dict.get('title', None)
uploader_id = info_dict.get('uploader_id', None)
print(f"[youtube] {video_title}: {uploader_id}")
return info_dict
def parse_metadata(metadata) -> dict:
"""
Parse metadata and send to discord.
After a video is done recording,
it will have both the livestream format and the mp4 format.
"""
# send metadata to discord
formats = metadata.get("formats", [])
# filter for ext = mp4
mp4_formats = [f for f in formats if f.get("ext", "") == "mp4"]
try:
format_ids = [int(f.get("format_id", 0)) for f in mp4_formats]
video_entries = sorted(set(format_ids).intersection(youtube_mp4_codes))
is_livestream = True
if len(video_entries) > 0:
# use video format id over livestream id if available
selected_id = video_entries[0]
is_livestream = False
except Exception as e:
print(e)
selected_id = mp4_formats[0].get("format_id")
is_livestream = False
return {
"selected_id": selected_id,
"is_livestream": is_livestream,
}
The above code is written in Python and contains functions for getting metadata for a YouTube video, parsing the metadata, and converting seconds to timecode. It also imports the necessary libraries including whisper, gradio, ffmpeg, yt_dlp, os, sys, and subprocess.
The get_video_metadata function takes a YouTube video URL as input and returns a dictionary containing metadata about the video such as the title and uploader ID. This function uses the YoutubeDL library to extract information about the video from YouTube.
The parse_metadata function takes the metadata dictionary as input and returns a dictionary containing the selected video format ID and a boolean indicating whether the video is a livestream or not. This function filters the available video formats to only include MP4 formats and then selects the video format with the highest priority (based on the priority list youtube_mp4_codes). If no MP4 format is available, it selects the first available format.
The second_to_timecode function takes a floating-point number representing a time in seconds as input and returns a string formatted as hh:mm:ss,ms (hours:minutes:seconds,milliseconds) where ms is the milliseconds portion of the time.
Note that the code also includes a list of YouTube format codes for livestreams (youtube_livestream_codes) and MP4 formats (youtube_mp4_codes).
def get_video(url: str, config: dict):
"""
Get video from start time.
"""
# result = subprocess.run()
# could delay start time by a few seconds to just sync up and capture the full video length
# but would need to time how long it takes to fetch the video using youtube-dl and other adjustments and start a bit before
filename = config.get("filename", "livestream01.mp4")
end = config.get("end", "00:15:00")
overlay_file = ffmpeg.input(filename)
(
ffmpeg
.input(url, t=end)
.output(filename)
.run()
)
def get_all_files(url: str, end: str = "00:15:00"):
metadata = get_video_metadata(url)
temp_dict = parse_metadata(metadata)
selected_id = temp_dict.get("selected_id", 0)
formats = metadata.get("formats", [])
selected_format = [f for f in formats if f.get("format_id", "") == str(selected_id)][0]
format_url = selected_format.get("url", "")
filename = "temp.mp4"
get_video(format_url, {"filename": filename, "end": end})
return filename
def get_text_from_mp3_whisper(inputType:str, mp3_file: str, url_path: str, taskName: str, srcLanguage: str)->str:
# remove the file if it exists
if os.path.exists("transcript.srt"):
os.remove("transcript.srt")
if os.path.exists("temp.mp4"):
os.remove("temp.mp4")
if os.path.exists("subtitled.mp4"):
os.remove("subtitled.mp4")
model = whisper.load_model("medium")
# options = whisper.DecodingOptions(language="en", without_timestamps=True)
options = dict(language=srcLanguage)
transcribe_options = dict(task=taskName, **options)
# return if url_path is not set, taskName is not set, srcLanguage is not set
if inputType == "url":
filename = get_all_files(url_path)
print("Retrieved the file")
result = model.transcribe(filename, **transcribe_options)
print("transcribing the file")
else:
result = model.transcribe(mp3_file, **transcribe_options)
# adjust for spacy mode
html_text = ""
lines = []
for count, segment in enumerate(result.get("segments")):
# print(segment)
start = segment.get("start")
end = segment.get("end")
lines.append(f"{count}")
lines.append(f"{second_to_timecode(start)} --> {second_to_timecode(end)}")
lines.append(segment.get("text", "").strip())
lines.append('')
words = '\n'.join(lines)
# save to transcript.srt
with open("transcript.srt", "w") as f:
f.write(words)
print("done transcribing")
input_file = 'temp.mp4'
subtitles_file = 'transcript.srt'
output_file = 'subtitled.mp4'
try:
print("attempt to output file")
(
ffmpeg
.input(input_file)
.filter('subtitles', subtitles_file)
.output(output_file)
.run()
)
except Exception as e:
print("failed to output file")
print(e)
output_file = "temp.mp4"
# return temp.mp4
return result.get("segments"), words, output_file
The get_text_from_mp3_whisper function takes several arguments including inputType, mp3_file, url_path, taskName, and srcLanguage. It first removes any existing files with names transcript.srt, temp.mp4, and subtitled.mp4.
It then loads a pre-trained model from whisper using the load_model function. The function checks the value of inputType to determine whether to transcribe a local mp3 file (mp3_file) or a video at a remote URL (url_path). If inputType is "url", it downloads the video from the remote URL using the get_all_files function and transcribes it. If inputType is "file", it transcribes the local mp3 file.
The transcribed segments are then saved to a file named transcript.srt. The function then attempts to add subtitles to the video by overlaying the saved SRT file onto a copy of the video file. The resulting file is saved as subtitled.mp4. If the overlaying process fails, it saves the resulting file as temp.mp4.
The function then returns the segments and the contents of the SRT file as a string, as well as the name of the resulting video file.
gr.Interface(
title = 'Download Video From url and extract text from audio',
fn=get_text_from_mp3_whisper,
inputs=[
gr.Dropdown(["url", "file"], value="url"),
gr.inputs.Audio(type="filepath"),
gr.inputs.Textbox(),
gr.Dropdown(["translate", "transcribe"], value="translate"),
gr.Dropdown(["Japanese", "English"], value="Japanese")
],
button_text="Go!",
button_color="#333333",
outputs=[
"json", "text", "file"
],
It seems that the code block is not complete, as there is no closing parenthesis for the gr.Interface function call. However, assuming that the rest of the code is present, this function call creates a user interface using the gradio library.
The interface has a title, “Download Video From url and extract text from audio”, and it takes in the following inputs:
A dropdown menu to select the input type (“url” or “file”).
An audio input to upload an audio file.
A textbox to enter the URL of a video.
A dropdown menu to select the task (“translate” or “transcribe”).
A dropdown menu to select the source language (“Japanese” or “English”).
The interface also has a button with text “Go!” and color “#333333”, and it outputs a JSON object, a string of text, and a file.
Using AI to transcribe videos has many practical benefits. Firstly, it enables the creation of accurate, searchable and accessible transcripts that can be used for a variety of purposes. Transcripts can be used to help people with hearing impairments to understand video content, as well as to provide captions and subtitles for non-native speakers of the video’s language. Transcripts can also be used to provide metadata for video content, making it easier to search and categorize. Additionally, transcripts can be used to analyze the content of video content, allowing for more effective search and retrieval of relevant information.
AI-based transcription is also faster and more cost-effective than traditional human transcription methods. With the advances in AI technology, transcription can be done much faster and at a lower cost than hiring human transcribers. This allows for more content to be transcribed in a shorter amount of time, and at a lower cost. Furthermore, AI-based transcription can be easily scaled up or down depending on the size of the content that needs to be transcribed.
Overall, using AI to transcribe videos is a useful and practical application of AI technology that has the potential to significantly improve the accessibility and usability of video content.
References#
Scrapping Superbowl results with pandas#
The Super Bowl is the championship game of the National Football League (NFL), which is played annually to determine the winner of the NFL season. The game is played on the first Sunday in February and is considered the biggest sporting event in the United States, attracting millions of viewers each year. The Super Bowl is also one of the largest events in the world of advertising, with many of the most expensive and highly-anticipated commercials airing during the broadcast. In addition to the game itself, the Super Bowl weekend has become a major cultural event, with parties, concerts, and other festivities taking place in the host city leading up to the game.
import requests
import pandas
import matplotlib
# read pandas dataframe from url
base_url = 'http://www.espn.com/nfl/history'
leaders_df = pandas.read_html(f"{base_url}/leaders", attrs={'class': 'tablehead'})[0]
winners_df = pandas.read_html(f"http://www.espn.com/nfl/superbowl/history/winners", attrs={'class': 'tablehead'})[0]
mvp_df = pandas.read_html("http://www.espn.com/nfl/superbowl/history/mvps", attrs={'class': 'tablehead'})[0]
print(leaders_df.head())
print(winners_df.head())
print(mvp_df.head())
This code uses the requests, pandas, and matplotlib libraries to retrieve and process data from three different URLs related to NFL history and the Super Bowl.
The first URL is for NFL leaders and the data is loaded into a pandas DataFrame called leaders_df. The second URL is for Super Bowl winners and the data is loaded into a pandas DataFrame called winners_df. The third URL is for Super Bowl MVPs and the data is loaded into a pandas DataFrame called mvp_df.
Finally, the code prints the first five rows of each DataFrame using the head() method of pandas DataFrames, which returns the first n (in this case, n=5) rows of the DataFrame.
0 1 2
0 Touchdown Leaders Touchdown Leaders Touchdown Leaders
1 RK PLAYER TD
2 1 Jerry Rice 208
3 2 Emmitt Smith 175
4 3 LaDainian Tomlinson 162
0 ... 3
0 Super Bowl Winners and Results ... Super Bowl Winners and Results
1 NO. ... RESULT
2 I ... Green Bay 35, Kansas City 10
3 II ... Green Bay 33, Oakland 14
4 III ... New York Jets 16, Baltimore 7
[5 rows x 4 columns]
0 ... 2
0 Super Bowl Most Valuable Players ... Super Bowl Most Valuable Players
1 NO. ... HIGHLIGHTS
2 I ... Two touchdown passes
3 II ... 202 yards passing, 1 TD
4 III ... 206 yards passing
These are the first five rows of each of the three pandas DataFrames that were created from the URLs related to NFL history and the Super Bowl.
The first DataFrame, leaders_df, shows the NFL touchdown leaders, including the rank, player name, and number of touchdowns scored.
The second DataFrame, winners_df, shows the results of each Super Bowl game, including the number of the Super Bowl, the winning team, and the result.
The third DataFrame, mvp_df, shows the most valuable player of each Super Bowl, including the number of the Super Bowl, the player’s name, and highlights of their performance.
# grab 4th column
# pandas drop first row of winners_df and change column names
# save winners_df to csv
winners_df.to_csv('winners_raw.csv', index=False)
winners_df = winners_df.iloc[1:]
winners_df.columns = winners_df.iloc[0]
winners_df = winners_df.iloc[1:]
print(winners_df.columns)
winners_df.to_csv('winners.csv', index=False)
print(winners_df.head())
sites_of_superbowl = winners_df['SITE'].unique()
print(sites_of_superbowl)
# for date column find the number of instances of Orange Bowl and plot it
# adjust all site to drop content in () and save to csv
winners_df_adjusted = winners_df.copy()
winners_df_adjusted['SITE'] = winners_df_adjusted['SITE'].str.replace(r'\(.*\)', '')
fig = winners_df_adjusted.groupby('SITE').size().plot(kind='bar', figsize=(10, 18)).get_figure()
This code continues processing the winners_df DataFrame, which contains information about the results of each Super Bowl game.
The 4th column of winners_df is not grabbed because the code does not contain any specific instructions to do so.
The first row of winners_df is dropped using the iloc method and the remaining rows are set as the new column names using the columns attribute. This DataFrame is then saved to a new CSV file called ‘winners.csv’ using the to_csv method of pandas DataFrames.
Next, the code uses the unique method of pandas Series to get the unique values of the ‘SITE’ column and store the result in a variable called sites_of_superbowl.
Then, a new DataFrame called winners_df_adjusted is created as a copy of winners_df and the ‘SITE’ column is adjusted to remove the content in parentheses using the str.replace method of pandas Series.
Finally, the code uses the groupby method of pandas DataFrames to group the DataFrame by the ‘SITE’ column and the size method to get the size of each group. The resulting pandas Series is plotted using the plot method with the kind argument set to ‘bar’ and the figsize argument set to (10, 18). The figure object is stored in a variable called fig.
Index(['NO.', 'DATE', 'SITE', 'RESULT'], dtype='object', name=1)
1 NO. ... RESULT
2 I ... Green Bay 35, Kansas City 10
3 II ... Green Bay 33, Oakland 14
4 III ... New York Jets 16, Baltimore 7
5 IV ... Kansas City 23, Minnesota 7
6 V ... Baltimore 16, Dallas 13
[5 rows x 4 columns]
['Los Angeles Memorial Coliseum' 'Orange Bowl (Miami)'
'Tulane Stadium (New Orleans)' 'Rice Stadium (Houston)'
'Rose Bowl (Pasadena, Calif.)' 'Superdome (New Orleans)'
'Silverdome (Pontiac, Mich.)' 'Tampa (Fla.) Stadium'
'Stanford (Calif.) Stadium' 'Jack Murphy Stadium (San Diego)'
'Joe Robbie Stadium (Miami)' 'Metrodome (Minneapolis)'
'Georgia Dome (Atlanta)' 'Sun Devil Stadium (Tempe, Ariz.)'
'Qualcomm Stadium (San Diego)' 'Pro Player Stadium (Miami)'
'Raymond James Stadium (Tampa, Fla.)' 'Reliant Stadium (Houston)'
'Alltel Stadium (Jacksonville, Fla.)' 'Ford Field (Detroit)'
'Dolphin Stadium (Miami)'
'University of Phoenix Stadium (Glendale, Ariz.)'
'Sun Life Stadium (Miami)' 'Cowboys Stadium (Arlington, Texas)'
'Lucas Oil Stadium (Indianapolis)'
'Mercedes-Benz Superdome (New Orleans)'
'MetLife Stadium (East Rutherford, N.J.)'
"Levi's Stadium (Santa Clara, Calif.)" 'NRG Stadium (Houston)'
'U.S. Bank Stadium (Minneapolis)' 'Mercedes-Benz Stadium (Atlanta)'
'Hard Rock Stadium (Miami)' 'SoFi Stadium (Inglewood, Calif.)'
The code above uses the pandas library to scrape data about the NFL Super Bowl winners, MVPs, and touchdown leaders from the ESPN website. It then saves the data in CSV format for future use.
It starts by reading the HTML tables from the website using the read_html method from the pandas library and storing the results in dataframes. The first dataframe, leaders_df, contains the touchdown leaders. The second dataframe, winners_df, contains the Super Bowl winners and results. The third dataframe, mvp_df, contains the Super Bowl MVPs.
The code then processes the winners_df dataframe to remove the first row and set the column names, which are the first row of the dataframe. The processed dataframe is then saved in a new CSV file called ‘winners.csv’.
Next, the code extracts the unique values of the ‘SITE’ column of the winners_df dataframe and stores the results in the sites_of_superbowl array. The code then creates a new dataframe called winners_df_adjusted that is a copy of the winners_df dataframe but with the content in the parentheses removed from the ‘SITE’ column. Finally, the code plots a bar chart of the number of instances of each site using the groupby and size methods from the pandas library and the plot method from the matplotlib library.
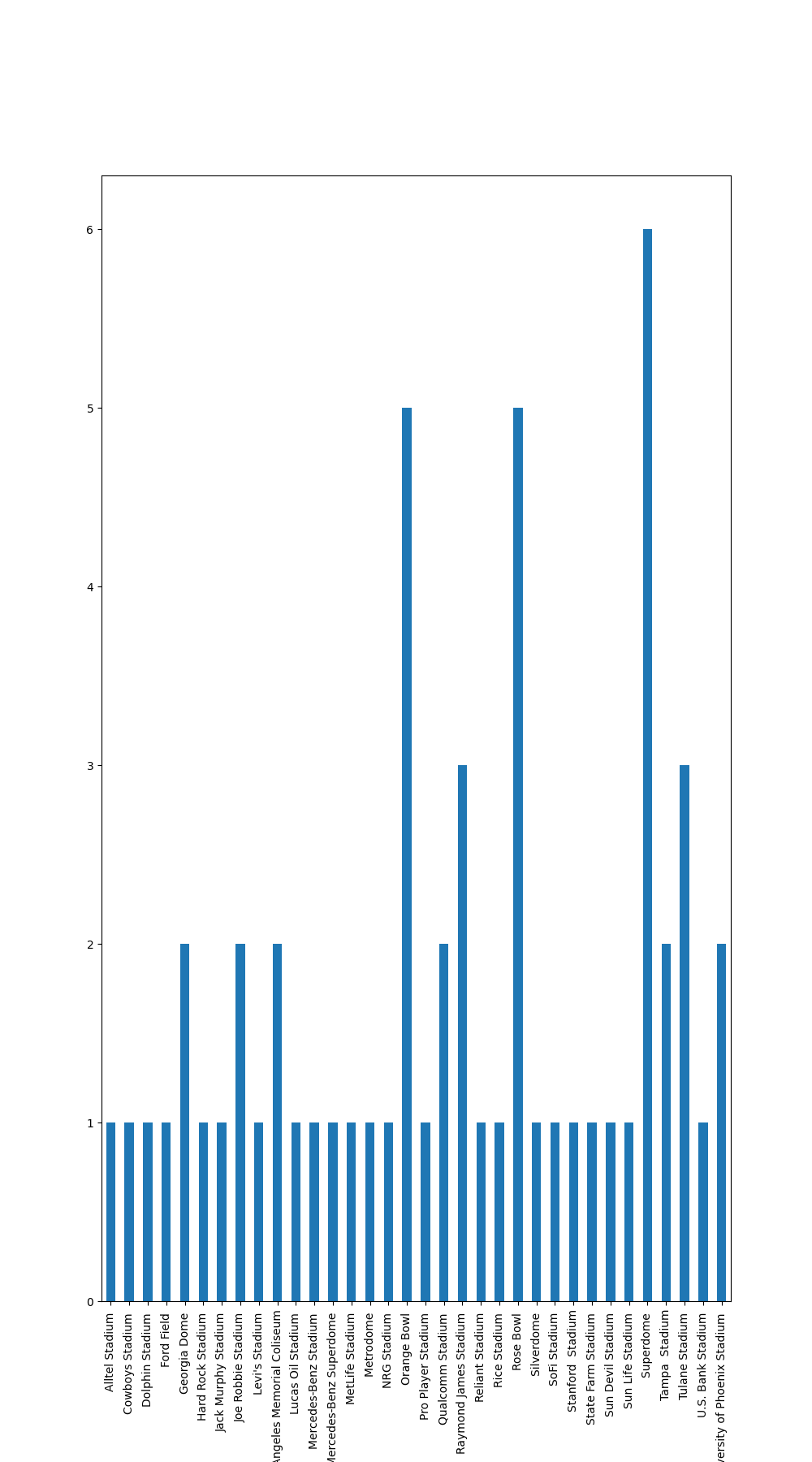 Yes, indeed! Web scraping is a powerful tool to collect data from websites and the combination with data visualization makes it even more valuable to understand and draw insights from the data. It’s also a great way to automate data collection and analysis tasks.
Yes, indeed! Web scraping is a powerful tool to collect data from websites and the combination with data visualization makes it even more valuable to understand and draw insights from the data. It’s also a great way to automate data collection and analysis tasks.
References#
Getting youtube livestream status#
YouTube is a video-sharing website where users can upload, share, and view videos. It was founded in February 2005 and later acquired by Google in November 2006. It has since become one of the largest and most popular websites on the internet, offering a wide variety of content, including music videos, educational videos, movie trailers, and more. Users can also interact with each other by commenting on videos, giving “thumbs up” or “thumbs down” ratings, and subscribing to other users’ channels. YouTube is available on various devices, including computers, smartphones, and smart TVs.
Transcribing Federal Reserve livestreams in real time is important for investors because the statements made by Federal Reserve officials can have a significant impact on financial markets. The Federal Reserve is the central bank of the United States, and its policies and statements on monetary policy, economic conditions, and interest rates can have a major effect on the stock market, the bond market, and the value of the US dollar.
By transcribing the livestreams in real time, investors can quickly and accurately obtain information and insights from the Federal Reserve’s statements. This can help them make informed investment decisions and respond to market changes as they occur. Additionally, real-time transcription allows investors to more effectively analyze and interpret the Federal Reserve’s statements, giving them a competitive advantage in a fast-paced and constantly-changing market.
In short, transcribing Federal Reserve livestreams in real time is important for investors because it allows them to stay up-to-date on the central bank’s statements and respond quickly to market changes, which can have a significant impact on their investments.
"""
author: FriendlyUser
description: grab livestream data from url using selenium, (need a browser for youtube)
create database entries to track livestreams, check if livestream is live or upcoming and exclude certain channels with never ending livestreams.
"""
import bs4
import time
from selenium import webdriver
import os
import dateparser
def get_livestreams_from_html(data: str):
"""
gets livestream from html from youtube channel and determines if it is live or upcoming.
Returns dict:
time: time of livestream
channel: channel name
status: LIVE or UPCOMING or none
"""
# get text data from url using requests
try:
soup = bs4.BeautifulSoup(data, "html.parser")
livestream_data = []
first_section = soup.find("ytd-item-section-renderer")
title_wrapper = first_section.find("ytd-channel-video-player-renderer")
if title_wrapper == None:
watch_link = first_section.find("a", {"class": "yt-simple-endpoint style-scope ytd-video-renderer"})
watch_url = watch_link.get("href")
else:
channel_title = title_wrapper.find("yt-formatted-string")
watch_link = channel_title.find("a")
watch_url = watch_link.get("href")
# get video_id
ytd_thumbnail_overlay_time_status_renderer = first_section.find("ytd-thumbnail-overlay-time-status-renderer")
# try to find ytd-video-renderer and get href
if ytd_thumbnail_overlay_time_status_renderer is None:
# try to grab upcoming livestream
scheduled_text = first_section.find("ytd-video-meta-block")
run_time = scheduled_text.get_text()
# parse strings like August 22 at 6:00 AM
# remove words like at
run_str = run_time.replace("Scheduled for", "").strip()
parsed_date = dateparser.parse(run_str)
livestream_data.append({"date": parsed_date, "status": "UPCOMING", "watch_url": watch_url})
else:
livestream_label = ytd_thumbnail_overlay_time_status_renderer.get_text()
if livestream_label is not None:
livestream_data.append({"date": None, "status": livestream_label.strip(), "watch_url": watch_url})
return livestream_data
except Exception as e:
print(e)
print("Error getting data from url")
return []
This code uses the BeautifulSoup library and Selenium WebDriver to scrape a YouTube channel for live stream data. The function get_livestreams_from_html takes in an HTML string as input and returns a list of dictionaries, each representing a live stream event.
The function first creates a BeautifulSoup object from the input HTML string and then searches the HTML tree for specific elements that contain information about the live streams. It checks if the live stream is currently happening or if it’s scheduled to happen in the future, and if it’s live, it checks if it’s never ending. If the live stream is never ending, the function does not include that event in the list of live streams.
The function uses the dateparser library to parse dates from strings, such as “August 22 at 6:00 AM”. The live stream events are returned as a list of dictionaries, each containing the date and time of the event, the channel name, and the status of the event (live or upcoming).
This code can be used as a starting point for a more comprehensive script that scrapes live streams from YouTube, but it may need to be adapted to fit the specific needs of the user.
def get_webdriver():
remote_url = os.environ.get("REMOTE_SELENIUM_URL")
if remote_url is None:
raise Exception("Missing REMOTE_SELENIUM_URL in env vars")
return webdriver.Remote(
command_executor=remote_url,
)
def get_html_from_url(url: str):
"""
gets html from url
"""
# get text data from url using requests
driver = get_webdriver()
driver.get(url)
time.sleep(10)
# return html from page source
return driver.page_source
if __name__ == "__main__":
html = get_html_from_url("https://www.youtube.com/c/YahooFinance")
livestream_data = get_livestreams_from_html(html)
base_url = "https://www.youtube.com"
# check if LIVE or UPCOMING
for livestream in livestream_data:
if livestream["status"] == "LIVE":
print("LIVE")
youtube_url = base_url + livestream["watch_url"]
data = {"youtube_url": youtube_url, "iteration": -1, "table_name": "YahooFinance"}
print(data)
elif livestream["status"] == "UPCOMING":
print("UPCOMING")
exit(0)
else:
print("NONE")
exit(1)
This code is using the Selenium WebDriver to automate the web browser and retrieve the HTML content of a YouTube channel. The channel URL is hardcoded as “https://www.youtube.com/c/YahooFinance” in the get_html_from_url function, but it could be updated to read from a configuration file, as noted in the TODO comment.
After retrieving the HTML, the code uses the get_livestreams_from_html function to extract information about the livestreams on the channel, if any. It then checks the status of each livestream, and if the status is “LIVE”, it prints the information, including the URL of the livestream on YouTube and some additional data. If the status is “UPCOMING”, the code exits with status code 0. If the status is neither “LIVE” nor “UPCOMING”, the code exits with status code 1.
References#
Natural gas Analysis#
Gas prices fluctuate due to a variety of factors, including changes in the cost of crude oil, which is the primary raw material used to produce gasoline, as well as changes in supply and demand for gasoline, taxes, and other costs associated with refining, storing, and transporting gasoline. Additionally, geopolitical events, such as conflicts or natural disasters, can also affect gas prices by disrupting the global oil market.
Cyclical stocks are stocks that tend to be sensitive to the economic cycle, meaning their prices tend to rise and fall with the overall health of the economy. These stocks are often associated with industries that are heavily influenced by consumer spending, such as retail, consumer durables, and homebuilding.
Cyclical stocks tend to perform well during economic expansions and periods of low unemployment, as consumers have more disposable income to spend on non-essential goods and services. However, during economic downturns and recessions, when consumer spending decreases, the profits and stock prices of companies in cyclical industries tend to decline.
Examples of cyclical stocks include those in the automotive, construction, housing, and consumer discretionary sectors.
A 3-month moving average is a technical indicator that is used to smooth out short-term fluctuations in a stock or index’s price, and to help identify longer-term trends. It is calculated by taking the average of a stock or index’s closing price over the past three months.
The idea behind a moving average is that it helps to filter out “noise” in the stock or index’s price, and to make it easier to spot trends. By averaging out the closing prices over a longer period of time, such as three months, the moving average smooths out any short-term volatility in the stock or index’s price, and makes it easier to identify longer-term trends.
Traders often use moving averages to help identify buy and sell signals. For example, if a stock or index’s price is above its 3-month moving average, it may be considered to be in an uptrend, and traders may buy the stock or index. Conversely, if a stock or index’s price is below its 3-month moving average, it may be considered to be in a downtrend, and traders may sell the stock or index.
# calculate average from daily data from natural gas futures from yahoo finance
import yfinance
import pandas as pd
import mplfinance as mpf
# read NG=F 2 years worth of data
nat_gas = yfinance.download("NG=F", start="2021-01-01", end="2023-01-01")
nat_gas['Month'] = pd.to_datetime(nat_gas.index)
# pad all date
# print(nat_gas.groupby(by=['Volume', 'Adj Close', pd.Grouper(key='Month', freq='3M')])['Open'].agg('mean'))
mths_3 = pd.date_range(end = nat_gas.index[-1], freq=pd.offsets.BQuarterEnd(),periods=8)
# mths_6 = pd.date_range(end = nat_gas.index[-1], freq=pd.offsets.MonthBegin(6),periods=4)
mth3 = (nat_gas
#filter for last three months
.loc[mths_3]
.groupby(["Month", "Volume"])
.agg(avg_ng_last_3_months=("Open","mean"))
)
print(mth3)
# for Bir.to (birchcliff energy, I use the following numbers for some estimations)
# random guess from last two quarters of profit
# at 4.558 assume 360 revenue for Q4 and 160M profit
# 475 revenue and 260M profit for Q4
# considering the investor presentation, thinking its closer to 360M revenue and 160 M profit.
quarterly_profit = 160
# 266.05M * 0.2
# if deliveries are 3 quarters behind then
quarterly_dividend = 266.05 * 0.2
print(quarterly_dividend)
remaining_revenue = quarterly_profit - quarterly_dividend
print(remaining_revenue)
# 176 debt
total_debt = 176
# max debt reduction (they target to get to 50M USD in debt)
min_debt_reduction = total_debt - 100
print(min_debt_reduction)
# bunch of risk of falling gas prices, but with new supply reduction from russia, doubt it would be so bad.
# save fig
mpf.plot(nat_gas,type='ohlc',mav=(30, 60, 90), volume=True, style='yahoo')
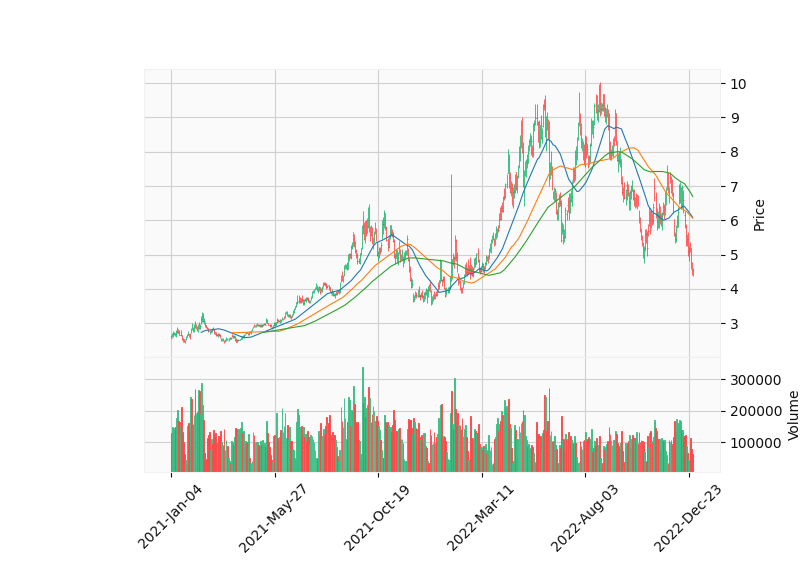
This script appears to be using the yfinance library to download historical data for natural gas futures (NG=F) from Yahoo Finance, for the period between January 1, 2021 and January 1, 2023. It then uses the Pandas library to create a new column in the dataframe called “Month” which is populated with the date of the data point, and converts it to a datetime object.
It then uses the Pandas library to create a date range for the last 8 quarters, and filters the dataframe to only include data points from those quarters. It then groups the data by the “Month” column and the “Volume” column, and calculates the average “Open” value for each group, which it saves to a new column in the dataframe called “avg_ng_last_3_months”.
It also appears to be doing some calculations related to a company’s profit, dividend, and debt, but it’s not clear how these calculations relate to the data being downloaded or how they are being used.
After that it is using mplfinance library to plot Open high low and close prices of natural gas with 30, 60 and 90 moving averages, and volume, and then it’s saving the graph with the name ng.png.
There are several libraries in Python that can be used to create financial plots, including:
Matplotlib: A widely-used library for creating static, animated, and interactive visualizations in Python. It can be used to create a wide variety of plots, including line plots, scatter plots, bar plots, and candlestick plots.
Plotly: A library for creating interactive visualizations in Python. It can be used to create a wide variety of plots, including line plots, scatter plots, bar plots, and candlestick plots.
mplfinance: A library built on top of matplotlib that is specifically designed for financial plotting. It can be used to create a wide variety of financial plots, including candlestick plots, barcharts and volume plots.
seaborn: A library for creating statistical visualizations in Python. It can be used to create a wide variety of plots, including line plots, scatter plots, bar plots, and heatmaps.
bokeh: A library for creating interactive visualizations in Python. It can be used to create a wide variety of plots, including line plots, scatter plots, bar plots, and candlestick plots.
All of these libraries have their own strengths and weaknesses, and the best choice will depend on the specific needs of the project. Some are better for creating static plots, while others are better for creating interactive visualizations. Some are better for working with large datasets, while others are better for creating highly customized visualizations.
Most of the libraries mentioned above require a basic understanding of the plotting and visualization concepts, Some of the libraries like mplfinance are built on top of matplotlib and are more specialized to financial plots, making it easier to create charts like candlestick charts and other financial plots.
Climate change is expected to have a significant impact on gas consumption as the world shifts towards cleaner and more sustainable energy sources. As temperatures rise and weather patterns become more extreme, the demand for natural gas is expected to increase in certain sectors such as power generation, as it is considered a cleaner alternative to coal and oil. However, in other sectors such as transportation, the demand for natural gas may decrease as electric vehicles and other alternative fuel vehicles become more prevalent.
The use of natural gas for power generation is expected to increase as countries look to phase out coal and reduce their greenhouse gas emissions. Natural gas is a less carbon-intensive fossil fuel and can be used in combination with renewable energy sources such as wind and solar power to provide a flexible and reliable source of electricity.
However, the transportation sector is also a significant contributor to global greenhouse gas emissions, and there is a growing movement to shift away from fossil fuels and towards electric and alternative fuel vehicles. As a result, the demand for natural gas as a transportation fuel is expected to decrease in the long term.
Overall, the impact of climate change on gas consumption is complex and will depend on a variety of factors, including government policies, technological advancements, and consumer preferences. It’s important to note that natural gas can be used as a transition fuel to decrease the use of coal and oil in power production and make the transition to renewable energy sources.